

Like, holy moly! Almost missed my calling.
Back in November of 2022, I stumbled upon a little startup from a couple of guys that were raised in Poland. After connecting with them, I began to snoop around the rest of the team. The team was short and nimble, the perfect scenario for big innovation. I noticed they had some ties to the UK and was quite aware at the volume at which venture capital was being deployed. Something was brewing. This was before their $2 million round. I knew it would cause major waves and plenty of delightfully democratizing disruption. The trends of faceless videos with voice synthesis intrigued me. Once you go ElevenLabs, you never go back (unless someone offers better pricing plans and service).
Getting back to the first ten labs that these folks had to go through before arriving at ElevenLabs; they've managed to create the best-of-breed in text-to-speech AI world that far surpassed any of the existing RLS or Tortoise alternatives. These methods require a lot of setup and wiring of so many things to make it even work and this was a one-click shop. During this discovery, I was involved with building out an Immersive Social Emotional Learning platform populated with a set of personas or characters that accompany you on your soul-bound journey of learning through interactions and serious play that raise one's emotional intelligence.
The only thing I have seen that could have once rivaled this was Lyrebird back in 2018 — almost the same level as they have arrived at now, six years later. For those that are not familiar with Lyrebird, they were acquired by Descript and provided the best text-based audio editing that started a trend in software after only five years of implementation. Seen Adobe Premiere lately? Yup. They finally caught up to a company from Canada that outperformed almost everyone in their industry for over half a decade. So many products that the AI Mafia released that no one is aware of, these building blocks ushered in a completely new approach to machine learning.
The conundrum we faced was doing traditional motion and performance capture which were attached to scripts, these are like poured concrete; it keeps the form and is not altered after the fact. The issue we faced was having to do multiple reshoots of all the performance captures for animation again if the script changed. Synthesized audio presented itself as the happy medium that provided copious amounts of flexibility in production.
To get a better understanding of what I'm talking about, here are some examples.
Text-to-Speech

Examples of voice libraries I have trained on my impressions, personas, and characters to showcase the capabilities and possibilities of variability in generation.
Turnbull Canyon
My mate Davide Bianca is a very talented creative director (BCN Visuals) for most of those fancy 3D Anamorphic billboards in Times Square and LA, not to mention the cool ads you see on The Sphere in Las Vegas. Well, he's got a little passion project that's grown into a full-blown enterprise. Check out Shifting Tides.









Do you see these %'s in the titles of the tracks? Those are the audio generation settings. There are multiple models for differing purposes, however, there are two main variables that are the baseline to voice synthesis and then there are some bells and whistles on other voice models within the software.
Then ElevenLabs released Projects and I was elated, to say the least. It was exactly what I needed to semi-automate production. Prepare a script. Export a PDF. Upload it. Then fix all the page errors and misalignment of chapters, and voila!

Hot Buttered Soul
My first attempt with a project and putting together an entire show or podcast. These were the building blocks. First, find the voice.


This is the identical script and model with the settings set to extremely weird. I tossed it in so you can listen to the range of how you can make the same words sound completely different or like completely different people.

Next, put together some background music and make a passable teaser.
Are you kidding me? This is all AI-synthesized audio of my voice. On demand!!
Next step, add some sound effects and play around some more. You're bound to have some fun and discover something you didn't know before you started.
I've come to realize that trying to create a show with a soulful vibe using an AI audio persona falls just shy, as it lacks the genuine soul. I mean, it sounds like me and can pass for me but there is still something contrived with how things are articulated and patterned. It's just off enough to notice it even more.
Token Wisdom

My second attempt at assembling a show with half automation and hoping that it was well above my estimations was very successful.

Still, there's a lot of work to put something decent together. Collectively, we're not there yet, but it does make for an easier and lighter production flow. This much I know. I've learned a few lessons from experimenting with these two long-form pieces of content. Now that I have gone off to learn a few more things, I can bring that back to streamline the production and make it sound even more authentic. Human performance capture on steroids.
Adding variation and emotion to the voice synthesis:
Trained My First 50 Voice Libraries
And this is the very first twenty or so of the first 50 voice libraries I trained. You'll notice slight variations in certain voices. These are showcasing the embedded software controls that allow for various versions of a voice in ElevenLabs. Mind you this is from last year and will give you some insights on how the backend can help you find your voice market fit. Now, I took it a step further and began training my own voice library in multiple performances to create a mini-library for that character's dynamic range of performance. I think around the 3-minute mark you'll hear a very prominent accent with slight variations on each one. Once you hear it in action, you'll get it. Options are great when you have finicky AI voice actors. You never know when you need to replace one!
First, you get the stability. Then you get the clarity and similarity enhancement. Then you get the style exaggeration. You do all those things, we'll throw in the speaker boost...
Press play 🧨
And you can just imagine the possibilities once you have a stack of custom voices. The stock ones are okay, however, I spent countless hours learning how to trick the AI into giving these performances the most life-like synthesis possible. Ever notice when AI generates voices, there are never any 'pops' or breaths? You either have a superb post-production pipeline or it's AI.
Speech-to-Speech based on Human Performance
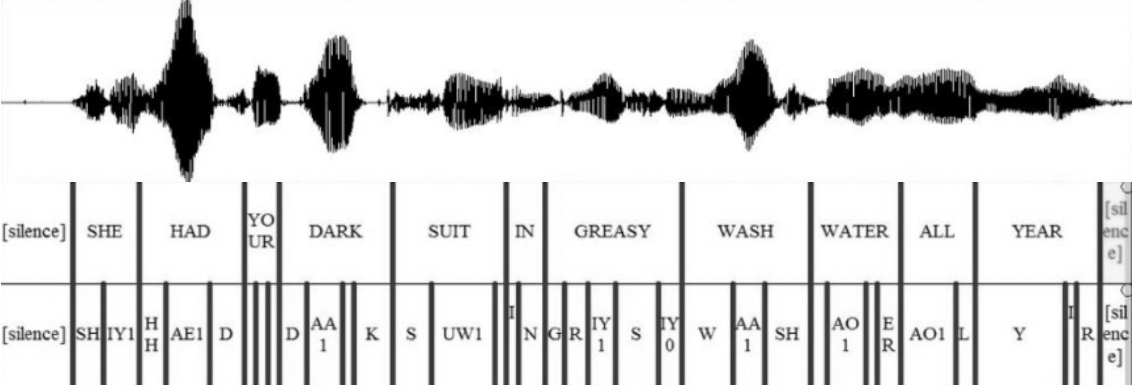
My performance. Their performance. Their impression of my performance.
The Joker - "Memories" Monologue
So I went on the internets and stumbled upon David Near's animated monologue he created a couple years back. So, I pulled the full video and clipped it to the sound sample I had. Then I used some fancy schmancy software to split the audio into stems and from there I mixed them all with out the vocal stem. Grabbed the video, the audio file, and my delivery of the Joker's monologue in this homage and recreation.
Not that we need a casting call after this, but you never know when you need a different kind of joker. Here are some interesting expressions of the same same.


Lord of the Rings: The Fellowship of the Ring


Three different female synthesized libraries mapping their best impression of my performance of the opening narration of Lord of the Rings. With some practice, I've been able to create voice libraries that can narrow in on a certain kind of voice, delivery, and cadence. In these examples, I utilized a closer latent space to generate from which creates a pseudo control-net or coherence in the model. Thus allowing for more consistent voices and performances. Would love to know which one you think delivered the performance that out-did the others. Which one of these voice talents would have gotten the gig? All three of these female voices are synthesized models that I created from male performances converted to female. Once that's complete, it's as simple as choosing the custom character to 'map' your voice with.



Old Spice Ad

Look at your man. Now back to me.

And in the example previous to this, I was looking for a very particular voice and delivery. Nothing has changed here except for...
If you can answer this and reach out to me, well, I'm going to figure out something I can gift you for being so bloody smart and savvy.



Creating Multiple Voice Libraries for One Persona in Various Emotional Deliveries
Yup. You read that correctly.
In my pursuit to capture 75 different versions of me, I learned that the voice models don't take direction well and can only control so much of the expression and delivery. And when you generate long sections, the engine seems to always putter out and the voice changes slightly at the end of a long token-consuming request. However, I found working in projects allows for a bit more freedom and can kind-a-sort-of tweak smaller sections to maintain greater consistency across the project.
But... I found a cheat code. Train multiple libraries in the same persona to deliver performance with a bit more dynamic range. So, I began testing a theory and began training a library based on a persona I call, "Pompous Pomp" — was going for a cross between Robin Leech and Idris Elba. After a few generations, I found it to be a bit basic. I then trained another one and another one. It would flip flop between an English and Australian accent. Same libraries, different settings.
I found the sweet spot. I trained the Baseline Pompous Pomp. Then came the Paced Pompous Pomp (for long-form content and reading). These two were perfect as is, one gave me the steady Eddy reading to you and making you feel real relaxed-like and the other puts a little pep in the stem and a little royal in your flush. The last one I did was over the top and accentuated, literally labeling it the Flourishing Pompous Pomp! Each segment is broken up into two sound samples from the same model and different generation parameters. The last example is the clip of my persona labeled as "The Count" =)

The Future of Voice
Goodbye Text-to-<fill_in_the_blank>.
Hello Speech-to-Everything-all-at-Once
So what's around the corner for voice and music synthesis at the tap tappy tap of your keyboard? I'll tell you what. If you start using this kind of software and watch YouTube, you'll realize the majority of the voices you hear have never said any of the words you're listening to. They've been conjured from an audio synthesis pipeline. InVideo, among others, have capitalized on this phenomenon and now with a simple script, they can perform their version of text-to-film.
The future is heavily automated and only means that if you're creating content, you're really going to have to incorporate some adaptability, resilience, and buckets of creativity. There is no limit to what can be done with this kind of audio generation. Looking forward to when the User Interface is, simply your voice.
Another great example of storytelling software that helps create without having to know any fancy editing or animation skills, is Augie Storyteller.
Stay tuned for more. We'll be listening to our very own Token Wisdom podcasts that cover the Time Well Spent and the Newest/Latest in weekly podcasts in the coming weeks. The show is designed so that each article or video can be distributed and shared on its own, thereby being short and sweet bite-size chunks.
Perfect for snacks!







Member discussion